👋 Hi, this is Mathias with your weekly drop of the 1% best, most actionable, and timeless resources to grow as an engineering or product leader. Handpicked from the best authors and companies.
As a Software engineer in a reasonably sized company, there's a high chance you deal with Kubernetes daily. But if this daily interaction is mostly doing kubectl set image, this article is for you.
Let's look at the Kubernetes API, an impressively consistent and extensive system.
"The Kubernetes API is massive - it has hundreds of endpoints. Luckily, it's pretty consistent, so one needs to understand just a limited number of ideas and then extrapolate this knowledge to the rest of the API."
The API is REST-ful and consists of Resources and Verbs. And all of these resources comply with a centrally stored schema: a Kind.
"In Kubernetes, a kind is the name of an object schema. Like the one you'd typically describe using a JSON schema vocabulary. In other words, a kind refers to a particular data structure, i.e. a certain composition of attributes and properties."
Because Kubernetes is an orchestrator, its main job is to orchestrate the setup and maintenance of Objects into a requested state. So an Object for Kubernetes is just that: the description of the desired state and metadata on its current status. A Pod or a Service are Objects: persistent entities that have a lifecycle inside the cluster.
"Objects of different kinds have different structures, but all Objects carry common metadata attributes like namespace, name, uid, or creationTimestamp."
Kubernetes API structure. Source: iximiuz.com
📗 While it just scratches the surface of the Kubernetes API, Ivan Velichko's Kubernetes API Basis is an excellent introduction to the atoms that make the Kubernetes API. Kinds, Objects, and Verbs are concepts you'll need to understand Kubernetes.
And even if you don't plan to read further, it's still a fascinating software architecture read on a highly-extensible distributed system.
Unless you've been living under a rock or were too busy getting your team to adopt the entire Netflix stack, you probably know Vercel. It's beautifully simple to use and gives you access to powerful edge hosting with almost no overhead.
How does this magic happen?
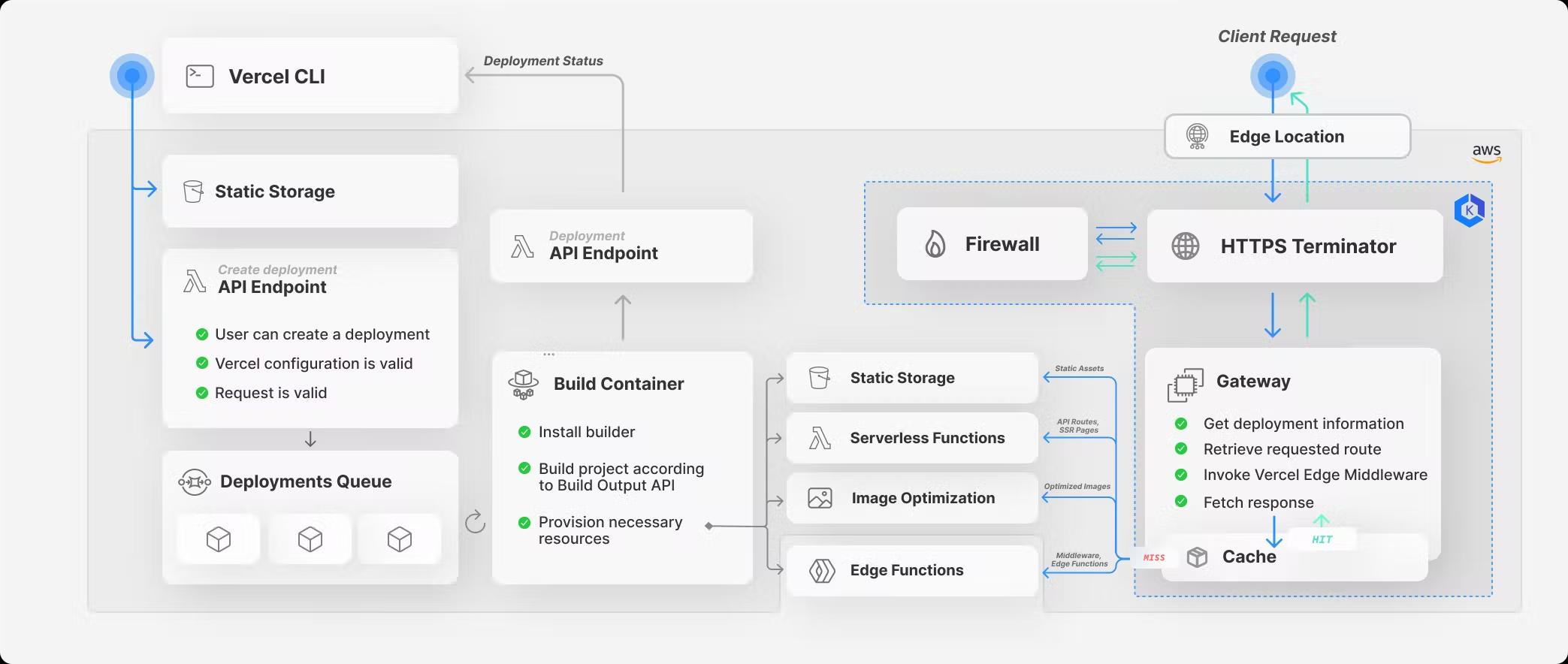
The hosting provider uses another, more prominent hosting provider: AWS. Vercel uses Amazon services to build your code directly from a git repository and deploy it at the edge.
Build phase
The code is first uploaded from Git to S3, and a build is queued.
A container picks up the build job from an SQS queue and runs the configured build steps.
"The build container creates a build output that runs on one of Vercel's supported runtimes, and provisions resources such as:
Serverless Functions for handling API routes and server-side rendered pages
Edge Functions for Middleware and other functions using the edge runtime
Optimized Images
Static output"
That build output is deployed, a Deployment object saved in the Vercel database: it's ready to serve traffic.
Request phase
Your Vercel URL resolves to an Anycast IP address: a global IP address that automatically connects the user to the nearest edge location, where the request enters AWS's network infrastructure.
The request enters Vercel's Kubernetes Cluster, which identifies the Deployment, validates the request, runs any configured edge middleware, and routes it to the correct resource.
If the request points towards runnable code, it runs on Lambda, and its response is returned through Vercel's infrastructure to the calling user.
Full overview of Vercel’s infrastructure. Source: vercel.com
📗 Lydia Hallie's Behind the scenes of Vercel's infrastructure is a well-rounded developer marketing article because it shows how much complexity Vercel abstracts for the user. And while I would have loved more details, looking beyond the marketing buzzwords, it's an interesting architectural peek at how the hosting provider works.
You should be reading academic computer science papers
Are you missing out on the key to becoming a better programmer?
"While the tutorials can help you write code right now, it's the academic papers that can help you understand where programming came from and where it's going."
Reading academic papers is the most underappreciated way to grow as a software engineer.
"Knowing the history of the computing concepts that you use every day unlocks a lot of understanding into how they work at a practical level."
And it's not just about bleeding-edge algorithms. Most atoms of modern software appeared first in a paper. Some date back from as far as the 60s, but you don't have to go that far to find gems.
Take the DynamoDB papers, for instance. They describe how the distributed database system works, which can help you make design decisions you'd never make without a grasp of its internals.
And if you're into bleeding edge software, or if your job involves dealing with problems only solved with them, then reading papers is an absolute necessity.
"I find papers to expand the idea of what's possible with the work you do," said Ashby. "They can help you appreciate that there are other ways to solve these problems."
📗 Ryan Donovan's You should be reading academic computer science papers explains how reading papers is a great way to stand on the shoulders of giants. And if you don't know where to start, Ryan suggests checking the Papers We Love repository and community.