
Learning from Giants #56
Platform Design isn't just design, Shopify's LLM chatbot architecture optimized for UX, and Everything you need to know about Message Queues.

👋 Hi, this is Mathias, back from holidays 😎 with your weekly drop of the 1% best, most actionable, and timeless resources to grow as an engineering or product leader. Handpicked from the best authors and companies. Guaranteed 100% GPT-free content.
Did a friend send this to you? Subscribe to get these weekly drops directly in your inbox. Read the archive for even more great content. Also: I share these articles daily on LinkedIn.
What it means to design a platform
"Platform design isn’t just another flavor of UX or product design. There are challenges, mental models, and requisite skills that set platform design apart."
As a product leader, designer, or engineer, understanding the differences between platform and application design can help create better strategies and powerful self-reinforcing loops.
What exactly sets platform design apart?
1. Interfaces. APIs, components, services. How they're available to the platform user can guide them into building amazing, or terrible experiences. Think both simple and flexible. Because of the nature of platforms, interfaces are often one-way door decisions that are costly to reverse and thus require extra care.
2. "Incentives drive the motivation of both platform- and end- users."
3. "Emergence is the open-ended feedback loop that platforms can create and maintain. By designing for Emergence, not against it, we enable users to discover applications we never imagined."
The most obvious dimension of platform design, Emergence, must be enabled, managed, and monitored purposefully.
4. Second-order thinking requires thinking two steps ahead and anticipating how the platform can drive positive loops and mitigate bad ones. The first step is for user usage, and the second is for users' use of platform-born tools.
📗 Matthew Strom is a platform design lead at one of the most impressive platform companies, Stripe. If you're building a platform, thinking about it from these angles may help you find the flywheel we're all after.
The architecture of the perfect UX for LLM chatbots
Shopify's Sidekick.
We've all experienced it: LLM chatbots are slow. It's an excellent challenge for product engineers aiming for a great experience because the classic request/response scheme doesn't work.
LLM chatbot answers are streams of tokens, that are turned into streams of characters. So, by leveraging streaming, we can cut that response time. Streaming will render responses token by token, turning it into the ChatGPT experience we know.
But LLM chatbots aren't helpful as is; they become useful when they can search for additional content and, more generally, use tools.
"The typical tool integration goes:
Receive user input.
Ask the LLM to consult one or more tools that perform operations.
Receive tool responses.
Ask the LLM to assemble the tool responses into a final answer."
This worsens our slowness problem because data can only be rendered after step 4. That can mean dozens of seconds of wait time. The Sidekick team's solution is interesting: de-couple to parallelize invocations.
"We've made a tweak to break the tool invocation and output generation out of the main LLM response, to let the initial LLM roundtrip directly respond to the user, with placeholders that get asynchronously populated."
That's a game changer because this architecture allows streaming the response without waiting for intermediate invocations. The UI orchestrates multiple multiplexed LLM streams to build the final response while rendering instantly to show the user maximum progress.
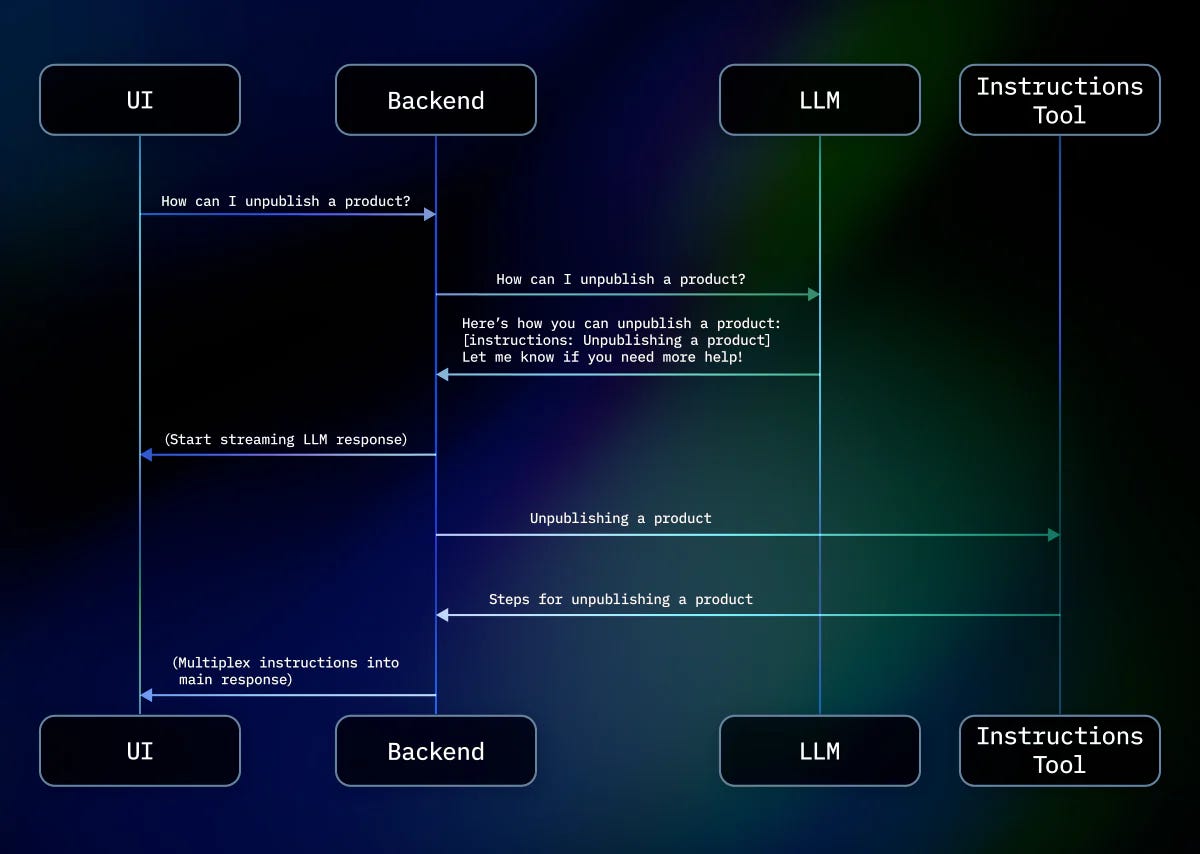
📗 Ates Goral's Sidekick's Improved Streaming Experience shows how much the unstructured aspect of LLMs allows engineers to be creative with architecture. Asynchronous tool resolution and the UI-driven process make a lot of sense in that context.
Everything you need to know about Message Queues
"Message Queues are a way to transfer information between two systems. This information—a message—can be data, metadata, signals, or a combination of all three."
While there are many different ways to transfer information, most lead to high coupling, 1-to-1 transfers only, and failure correlation.
"[With a message queue], one system is decoupled from the other in terms of responsibility, time, bandwidth, internal workings, load and geography."
Queues' killer feature is this decoupling. But as with everything software, there is no silver bullet, and decoupling comes with its trade-offs. Even though it's often system-specific, these usually are latency, consistency, and complexity.
When evaluating queues, you must look at a few dimensions:
Delivery guarantees can be At-Least Once, At-Most Once, or Exactly Once.
While Exactly Once is the best-sounding one, it's also the trickiest and, in most cases, a big smoke screen for complexity. If you don't know what to pick, go for At-Least Once.
"[At-Least Once] is the most common delivery mechanism, and it's the simplest to reason about and implement. If I have a message for you, I will read it to you, and keep doing so again and again until you acknowledge it."
By architecting your code for failure and retries, you'll build a significantly more resilient system than praying for at least once delivery guarantees to do the job for you.
Strict ordering vs. parallelism.
Again, the best-looking guarantees are also the most limiting. Opting for messages to be strictly processed in the order they were published makes parallelized processing forbidden and puts a speed limit on the overall process.
📗 Sudhir Jonathan 's The Big Little Guide to Message Queues is an excellent introduction to queues and their main attributes. If you're reading this article and still think that you need Exactly Once and Strict Ordering, here's a last piece of wisdom from Sudhir:
Most problems that seem like they have a hard FIFO requirement can often lend themselves to parallelism and out-of-order delivery with a little bit of creativity."
"Designing our messages to allow for out-of-order delivery and idempotency makes the system more resilient in general, while also letting use more parallel messaging systems—often saving time, money and a lot of operational work."