
Learning from Giants #71
Stripe's global money tracking data system, Happy GMV as an alternative to NPS, the LSM tree data structure, and a fantastic re-post on how Engineering levels can't be indexed on scope only.

Hi! This is Mathias with your weekly drop of the 1% best, most actionable, and timeless resources to grow as an engineering or product leader. Handpicked from the best authors and companies. Guaranteed 100% GPT-free content.
I got feedback that not everyone reads work-related articles on Saturdays (fair enough). So I’ll try sending them on Tuesdays for a few weeks!
Did a friend send this to you? Subscribe to get these weekly drops directly in your inbox. Read the archive for even more great content. Also, I share these articles daily on LinkedIn.
Ledger: Stripe’s system for tracking and validating money movement
Payments are a complex industry to scale because you're functionally (and legally) required to care about every single penny, regardless of your scale. As they scale to billions of payments daily and hundreds of third parties, the full explainability and reconciliation of theory with the actual bank accounts can become a significant issue.
👉 That's what the Data Quality Platform and Ledger team at Stripe set out to solve.
"Stripe supports more than 135 currencies and payment methods through partnerships with local banks and financial networks in 185 countries."
"Each day, Ledger sees five billion events and 99.99% of our dollar volume is fully ingested and verified within four days"
1. The Data Quality (DQ) Platform
The data quality platform standardizes and centralizes all money movements at Stripe in a database they call Ledger. The platform then offers observability workflows on top of Ledger.
The centralization aspect is super important. Dozens of teams work separately to integrate with local banks and payment providers. They each make design decisions to optimize for their providers and end up with different systems. These systems are nearly impossible to track globally.
2. Ledger: the underlying database
"We want to represent all activity on the Stripe platform in a common data structure that can be analyzed by a single system."
"Ledger encodes a state machine representation of producer systems, and models its behavior as a logical fund flow—the movement of balances (events) between accounts (states)."
So Ledger tracks and analyses each transaction passing through dozens of distributed systems as if it were part of one unified system. Because it does double-entry bookkeeping with these events and accounts, if money gets repeatedly stuck in a system or state, the balance of that state will immediately grow and trigger alerts.
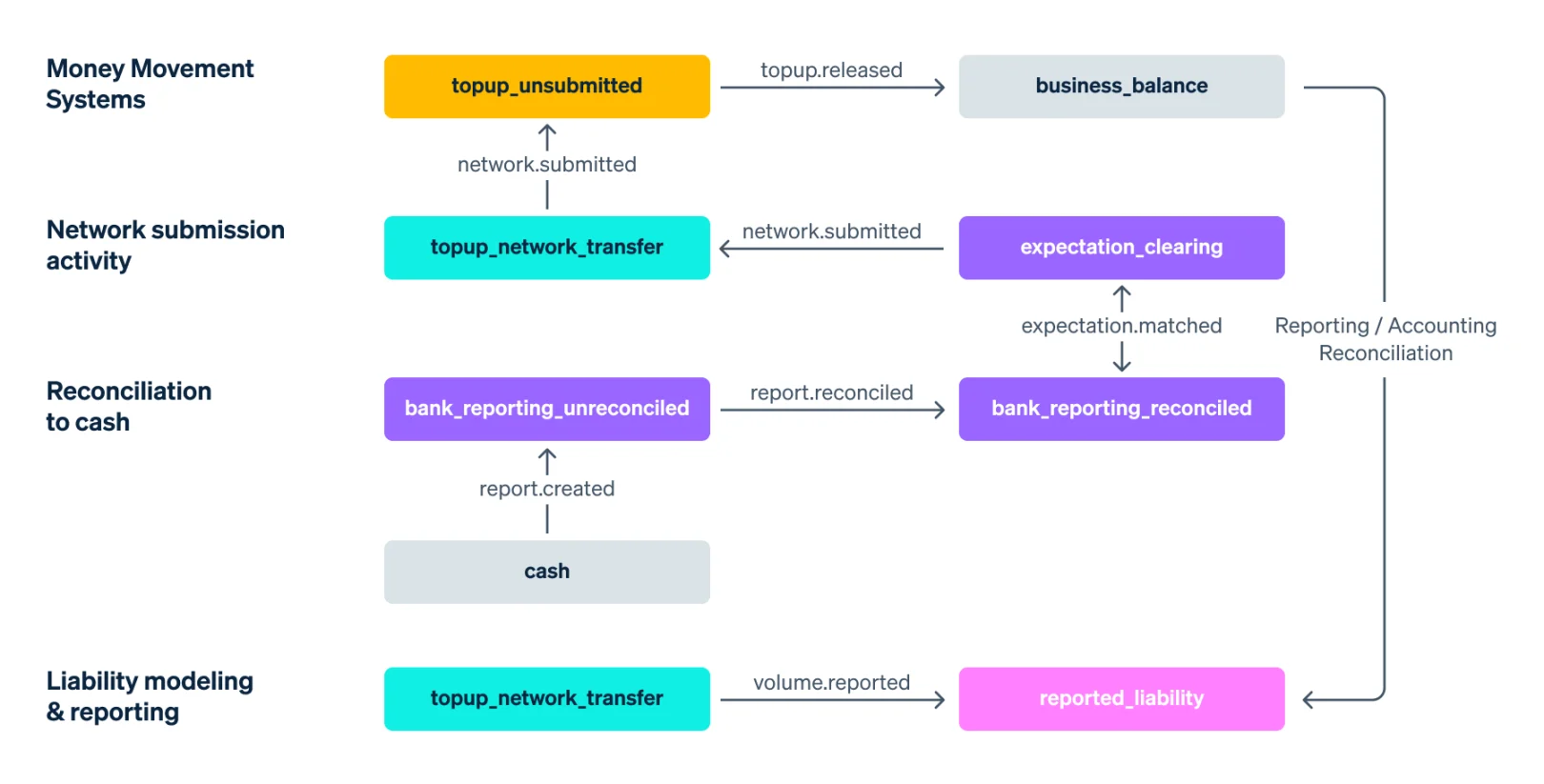
3. Data quality metrics, alerts, and remediation
"We analyze these [transaction-level data flows] with a set of trustworthy DQ metrics that measure the health of a fund flow. Clearing (did the fund flow complete correctly), Timeliness (did the data arrive on time), and Completeness."
"These measurements roll up to create a unified DQ score [...] turning a complex distributed analysis problem into a straightforward tabulation exercise"
The team built an entire observability stack on top of Ledger. Because they know who owns what, teams are alerted in real-time of metric drops and can easily see the impact of deployment and bug fixes.
"Combined, we have the ability to measure and analyze data quality, identify root-cause problems, and flexibly interact with the underlying data constructs to manage our problem load over time."
📗 Ilya Ganelin's Ledger: Stripe's system for tracking and validating money movements is a fascinating peek at the system, keeping the payment behemoth's systems sane, explainable, and reliable. It shows how much value can be created by solving problems with the right system design and abstractions and how that can scale to solve a global problem thanks to the software's near-infinite scale.
Measuring Happy GMV, and why I’m over Net Promoter Score.
1. NPS may not be the right north star metric.
"How NPS is calculated makes it an easily gamed, statistically noisy measure of intent, not of behavior."
It also is largely insignificant in early-stage companies because of the smaller sample size.
"What’s critical for any company to keep in their purview is [..] how much happier a person is when they use your product versus any substitute."
"If you make your customers happy enough, you become indispensable. That’s the key to achieving net revenue retention (and organic growth). A noisy algorithm based on how likely someone says they are to refer a friend or colleague is not."
2. Tracking Happy GMV
Sarah Tavel recommends looking at another metric she calls Happy GMV.
"Ask yourself “what is my best guess at the buyer and seller experience that will lead to retention?” and then measure the percentage of your potential buyers and sellers that get that experience."
"The GMV that qualifies is your Happy GMV."
She gives the example of a ride-sharing marketplace. An initial guess for rider-happy GMV could be the percentage of riders who find a driver quickly and rate them 4 or 5 stars.
Happy GMV is a leading metric and is much more actionable than NPS! You can use it to make daily operational decisions and prioritization.
"Over time, as your understanding of your customers improves and you start to have statistical significance in your cohorts, you’ll be able to tune your “Happy GMV” thresholds to more accurately reflect the experience that leads to retention and keep you focused on the most important levers."
📗 Sarah Tavel 's Measuring Happy GMV and Why I’m Over Net Promoter Score is a super actionable article for most companies and, in particular, marketplaces. Sarah has been a long-time partner at Benchmark, a Tier 1 super opinionated VC fund with deep expertise in marketplaces.
Understanding LSM Trees: What Powers Write-Heavy Databases
Cassandra, ScyllaDB, RocksDB, Google BigTable, and many other databases share one thing. They all use the same core data structure to read and write data, albeit with different implementations, because it allows for write-heavy workloads.
That data structure is the log-structured merge tree (LSM tree). Here's a super gentle introduction:
1. The Write path
"The write path is optimized by only performing sequential writes"
That's the main point. LSM trees only write large sequential (i.e. sorted by key) blobs of data to disk. Since they're sorted, they're a lot easier to query when looking for a specific key. These blobs are called segments or runs and are part of the Sorted String Table (SSTable).
SSTable doesn't work independently because writes do not come as large, pre-sorted blobs of data. They come as individual, unorganized key+value instructions.
"This is solved by using an in-memory tree structure. This is frequently referred to as a memtable."
"As writes come in, the data is added to this red-black tree. Our writes get stored in this red-black tree until the tree reaches a predefined size."
When the Memtable is large enough, it's written to disk, adding a new segment to our SSTable.
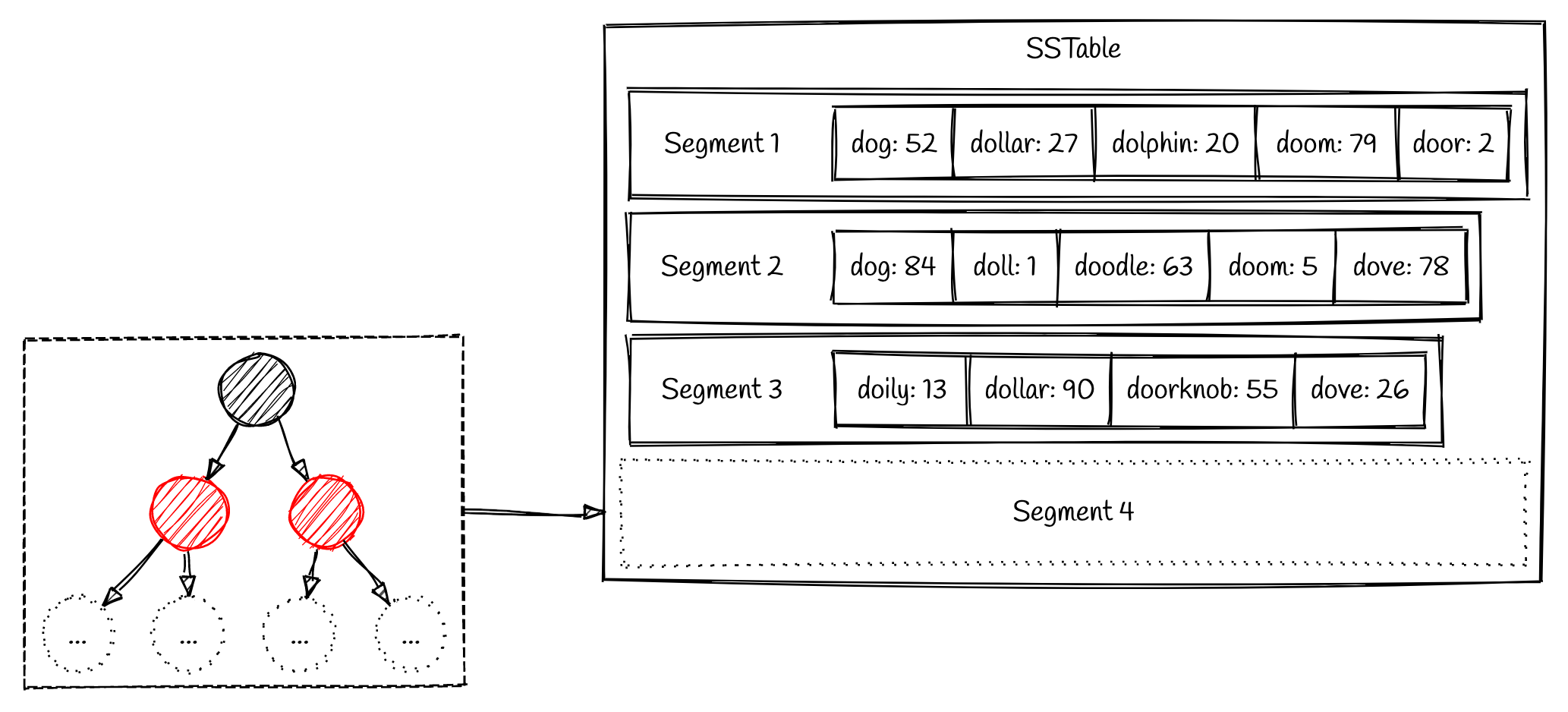
2. The Read path.
Finding a specific value in the SSTable requires scanning all segments from the most recent and stopping once the given key is found. In practice, databases use optimizations like indexes to help with scanning.
"What about looking up records that do not exist? We will still end up looping over all segment files and fail to find the key in each segment. This is something that a bloom filter can help us out with."
The Bloom filter can tell you it's 100% sure that some keys aren't in the dataset, with high compression, at the cost of being wrong in rare instances.
3. Optimization
You may think the performance must grow terribly with the number of segments. That is correct.
"These segment files need to be cleaned up and maintained in order to prevent the number of segment files from getting out of hand. This is the responsibility of a process called compaction. Compaction continuously combines old segments together into newer segments."
📗 Braden Groom's Understanding LSM Trees: What Powers Write-Heavy Databases is the best quick introduction to the data structure you'll find online. It may seem simple in the article, but each concept varies widely in implementation from one database to the other, with some small tricks everywhere to push performance. Although it's a 2020 article, it's not even on the Internet anymore, so thanks to the Internet Archive for keeping it up!
Top 0.1% re-post: Engineering Levels: Avoiding the Scope Trap
All tech companies end up building an engineering ladder. It makes sense for engineers to have a clear path forward. When they do, they often are heavily inspired by the dozens of publicly shared ladders.
That’s what Honeycomb did at first, but soon they started seeing gaps and small unsettling details. The biggest one? The importance that they gave to growing scope compared to other criteria.
“A ladder that conflates advancement with scope is a ladder that only rewards engineers who work on the largest projects. This doesn’t seem fair.”
“More often than not, scope is the enemy. We would rather reward engineers who find clever ways to limit scope by decomposing problems in both time and size.”
📗 Honeycomb’s Engineering Levels: Avoid the Scope Trap is an eye-opening post on how the company defined engineer career growth. It’s great because Ben Darfler explains the problems with their current solution and how they fixed them. It's super actionable and relatable.
The main result is a two-dimensional ladder, adding ownership to balance the impact of scope.

“Scope progresses from focusing on tasks to features to projects, products, and the company as a whole.”
“Ownership progresses from focusing on the execution of work to the process of delivering work, to the discovery of solutions to deliver, to the discovery of problems to solve.”